Counting Lines of a Text File in C#, the Smart Way
Counting the lines of a text file may not seem very exciting but recently I had to deal with a number of large files (for an upcoming article which you will soon read about on this blog) and one of the operations that I had to do was to count the number of lines but at the same time ensuring that I am nice to the .NET Garbage Collector and don’t cause any blocking collection.
So in this article we are going to have a look at how you can (micro)-optimise this seemingly easy task.
Sample Data
Before we start we need to have some sort of sample data we can use to benchmark and measure the performance of our algorithms.
We will be running our algorithms against 5 text files I have produced with each increasing in size starting from 6MB going all the way to 37GB. Every file consists of a word in each line also every smaller file is a subset of its larger brother (or sister or gender-neutral sibling).
Here’s the summary of our files:
Name Size(KB) Lines
1.txt 6,516 714,584
2.txt 12,995 1,410,082
3.txt 370,180 32,245,593
4.txt 3,721,999 332,799,453
5.txt 37,089,272 3,261,066,928
No Cheating
When benchmarking disk I/O operations it is important to remember to clear the Windows File Cache before each run otherwise instead of reading the data directly from the file we will read it from the RAM which can skew the results dramatically; Therefore, we will use RAMMap from the Sysinternals suite to clear the cache before each run.
Okay now that we have all of the formality out of the way let’s start counting some lines!
The Simple Way
The simplest way to get the number of lines in a text file is to combine the File.ReadLines method with System.Linq.Enumerable.Count. The ReadLines method returns an IEnumerable<string> on which we can then call the Count method to get the result. Here’s how:
public long CountLinesLINQ(FileInfo file) =>
File.ReadLines(file.FullName).Count();
Let us benchmark this nice and short method and see how it does against our files.
private void Benchmark(FileInfo file)
{
Console.WriteLine(nameof(CountLinesLINQ));
Stopwatch sw = Stopwatch.StartNew();
int count = CountLinesLINQ(file);
sw.Stop();
Console.WriteLine("{0} | {1} | Gen0 - {2} | Gen1 - {3} | Gen2 - {4}",
file.Name,
sw.Elapsed.ToString(),
GC.CollectionCount(0).ToString("N0"),
GC.CollectionCount(1).ToString("N0"),
GC.CollectionCount(2).ToString("N0"));
}
All we are doing here is run the method once for each of our input files (remembering to clear the cache before each run) and output the time taken as well as the number of times GC kicked in across all generations.
On my machine with a 1TB 7200 RPM 64MB cache HDD, Here’s what I get:
CountLinesLINQ
1.txt | 00:00:00.5933717 | Gen0 - 4 | Gen1 - 0 | Gen2 - 0
2.txt | 00:00:00.6265670 | Gen0 - 8 | Gen1 - 0 | Gen2 - 0
3.txt | 00:00:03.4404236 | Gen0 - 210 | Gen1 - 0 | Gen2 - 0
4.txt | 00:00:30.1371443 | Gen0 - 2,274 | Gen1 - 3 | Gen2 - 0
5.txt System.OverflowException: Arithmetic operation resulted in an overflow.
Oops! Everything was going well until we got an OverflowException, why?
Well, the System.Linq.Enumerable.Count extension method on File.ReadLines returns an Int32 which has a max value of 2,147,483,647 and as we saw earlier, there are over 3 billion lines in the 5.txt file so no surprise there.
Also notice the number of GC_s that took place, we didn’t have any _Gen2 collection and that’s mainly due to the fact that we don’t need to hold on to each line read from the file so nothing survives the Gen1 collection but even without the expensive Gen2 collection we are still causing Gen0 and Gen1 which are both blocking operations requiring all user threads to be suspended.
Let’s first fix that OverflowException. You may have realised that we should have used the System.Linq.Enumerable.LongCount as opposed to System.Linq.Enumerable.Count which as the name suggests returns an Int64 but why not avoid LINQ altogether.
Slightly Less Simple Way
In the LINQ version, all the File.ReadLine does is new-up a StreamReader and yield return every line read from the file as an IEnumerable<string> which we then call System.Linq.Enumerable.Count on, so why don’t we do that ourselves this time avoiding the OverflowException:
public long CountLinesReader(FileInfo file)
{
var lineCounter = 0L;
using(StreamReader reader = new(file.FullName))
{
while(reader.ReadLine() != null)
{
lineCounter++;
}
return lineCounter;
}
}
Again nothing really complicated here, we have the lineCounter declared as Int64 which we then increment every time a line is read from the reader. Okay, let’s benchmark it:
CountLinesReader
1.txt | 00:00:00.5690903 | Gen0 - 4 | Gen1 - 0 | Gen2 - 0
2.txt | 00:00:00.6243011 | Gen0 - 8 | Gen1 - 0 | Gen2 - 0
3.txt | 00:00:03.2662413 | Gen0 - 210 | Gen1 - 0 | Gen2 - 0
4.txt | 00:00:29.3749685 | Gen0 - 2,274 | Gen1 - 2 | Gen2 - 0
5.txt | 00:04:28.1865611 | Gen0 - 22,663 | Gen1 - 25 | Gen2 - 2
The results are almost identical albeit slightly faster compared to the LINQ version but this time we managed to handle the 5.txt file. So can we do better? Is there a way to count the lines without allocating anything on the heap so that GC doesn’t have to run? After all we don’t really care about the content of the lines. Hmm…
What If…
what if we go through the file one character at the time and every time we encounter an end-of-line character we increment our counter. Sounds pretty easy but before jumping to the implementation let’s remember that there are 3 different flavors of end-of-line characters:
- Carriage Return (
\r) used in Macintosh - Line Feed (
\n) used in UNIX - Carriage Return Line Feed (
\r\n) used in MS-DOS, Windows, OS/2
Even though \r\n is the most used end-of-line character these days but we still need to make sure our algorithm can handle other flavors.
So what if we do this:
private const char CR = '\r';
private const char LF = '\n';
private const char NULL = (char)0;
public static long CountLinesSmarter(Stream stream)
{
Ensure.NotNull(stream, nameof(stream));
long lineCount = 0L;
byte[] byteBuffer = new byte[1024 * 1024];
char prevChar = NULL;
bool pendingTermination = false;
int bytesRead;
while ((bytesRead = stream.Read(byteBuffer, 0, byteBuffer.Length)) > 0)
{
for (int i = 0; i < bytesRead; i++)
{
char currentChar = (char)byteBuffer[i];
if (currentChar == NULL) { continue; }
if (currentChar == CR || currentChar == LF)
{
if (prevChar == CR && currentChar == LF) { continue; }
lineCount++;
pendingTermination = false;
}
else
{
if (!pendingTermination)
{
pendingTermination = true;
}
}
prevChar = currentChar;
}
}
if (pendingTermination) { lineCount++; }
return lineCount;
}
Take your time to study what it actually does but all it is doing is incrementing a counter whenever it sees an end-of-line character.
Now that we have a working algorithm why don’t we also sprinkle some C#7 goodness over it! We can rewrite the body of the for loop as a switch statement with some pattern matching case blocks. You can read more about this feature HERE.
That then gives us:
public static long CountLinesSmarter(Stream stream)
{
Ensure.NotNull(stream, nameof(stream));
long lineCount = 0L;
byte[] byteBuffer = new byte[1024 * 1024];
char prevChar = NULL;
bool pendingTermination = false;
int bytesRead;
while ((bytesRead = stream.Read(byteBuffer, 0, byteBuffer.Length)) > 0)
{
for (int i = 0; i < bytesRead; i++)
{
char currentChar = (char)byteBuffer[i];
switch (currentChar)
{
case NULL:
case LF when prevChar == CR:
continue;
case CR:
case LF when prevChar != CR:
lineCount++;
pendingTermination = false;
break;
default:
if (!pendingTermination)
{
pendingTermination = true;
}
break;
}
prevChar = currentChar;
}
}
if (pendingTermination) { lineCount++; }
return lineCount;
}
Decisions Decisions
In terms of readability, both versions look pretty similar but which one should we pick? Is there any performance difference between the two versions? hmm…
Profiling Time
Let’s take our dotTrace profiler for a spin. We are going to use the line-by-line profiling which will give us the most accurate timing information on each statement we execute.
First the version with the if statement:
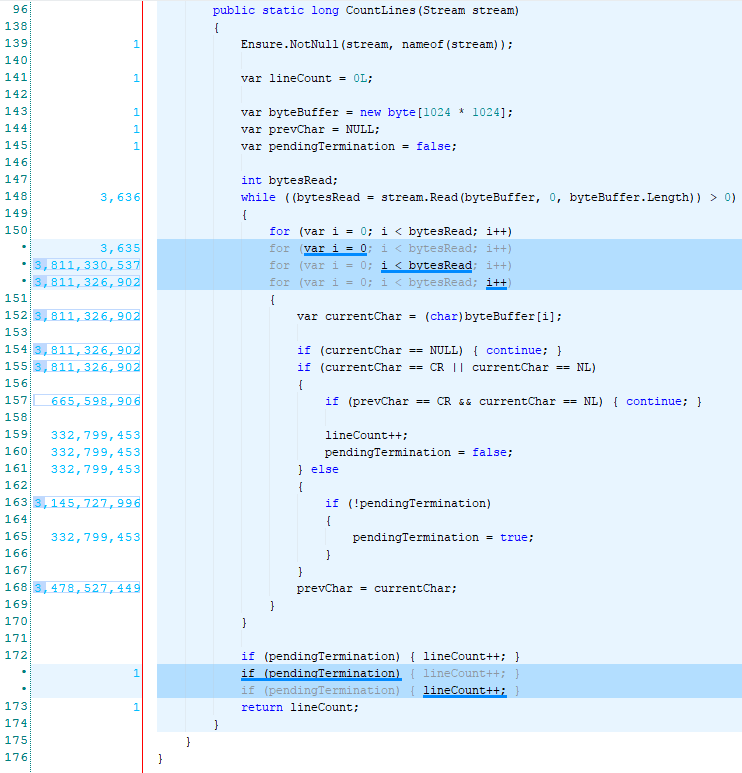
And now the one with the switch statement:
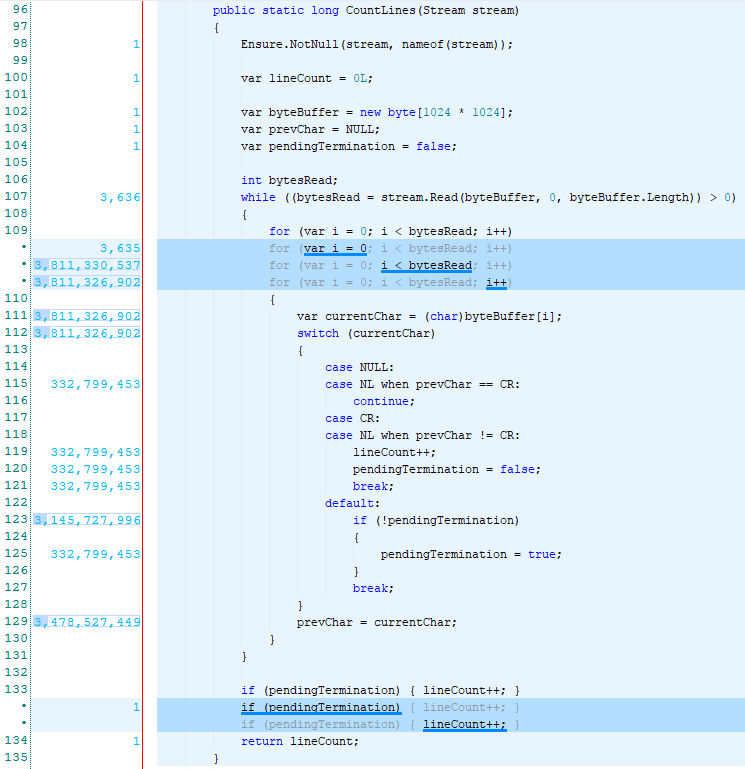
I let you go through the result at your leisure but a simple summing up of the numbers shows us that the switch version executes 15% fewer statements than the if version. So there we go, we know which version to pick.
If Switch
---------------------------
1 1
1 1
1 1
1 1
1 1
3,636 3,636
3,635 3,635
3,811,330,537 3,811,330,537
3,811,326,902 3,811,326,902
3,811,326,902 3,811,326,902
3,811,326,902 3,811,326,902
3,811,326,902 332,799,453
665,598,906 332,799,453
332,799,453 332,799,453
332,799,453 332,799,453
332,799,453 3,145,727,996
3,145,727,996 332,799,453
332,799,453 3,478,527,449
3,478,527,449 1
1 1
1
--------------------------------------
27,677,697,586 23,533,571,231
Refactor
Our Switch algorithm doesn’t look too bad but the fact that we have created a state-machine looks less satisfying to me so why don’t we refactor it slightly and see if we can reduce the number of comparisons we make.
public static long CountLinesSmarter(Stream stream)
{
Ensure.NotNull(stream, nameof(stream));
long lineCount = 0L;
byte[] byteBuffer = new byte[1024 * 1024];
char detectedEOL = NULL;
char currentChar = NULL;
int bytesRead;
while ((bytesRead = stream.Read(byteBuffer, 0, byteBuffer.Length)) > 0)
{
for (int i = 0; i < bytesRead; i++)
{
currentChar = (char)byteBuffer[i];
if (detectedEOL != NULL)
{
if (currentChar == detectedEOL)
{
lineCount++;
}
}
else if (currentChar == LF || currentChar == CR)
{
detectedEOL = currentChar;
lineCount++;
}
}
}
// We had a NON-EOL character at the end without a new line
if (currentChar != LF && currentChar != CR && currentChar != NULL)
{
lineCount++;
}
return lineCount;
}
This time we first try detecting the end-of-line character and then once we have it we can just check for that character and increment our counter without having to keep track of the previous character.
Let us see what the profiler says this time:
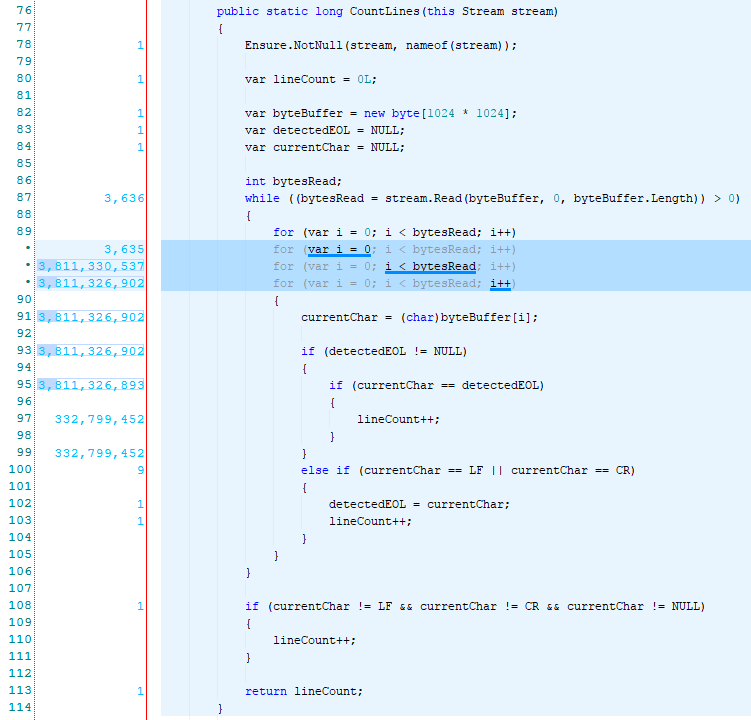
I like the smell of less statements to execute in a for loop!
Micro-Micro-Optimisation
By looking at the profiling sessions above you may jump to the conclusion that since we are spending too much time in the for loop why not unroll it.
For those unfamiliar with the concept of Loop Unrolling, it is an optimisation technique with the goal of reducing the overhead of a loop by executing fewer iterations but doing more work per iteration. So if we were to unroll the above implementation we can come up with something like:
public static long CountLinesMaybe(Stream stream)
{
Ensure.NotNull(stream, nameof(stream));
long lineCount = 0L;
byte[] byteBuffer = new byte[1024 * 1024];
const int BytesAtTheTime = 4;
char detectedEOL = NULL;
char currentChar = NULL;
int bytesRead;
while ((bytesRead = stream.Read(byteBuffer, 0, byteBuffer.Length)) > 0)
{
int i = 0;
for (; i <= bytesRead - BytesAtTheTime; i += BytesAtTheTime)
{
currentChar = (char)byteBuffer[i];
if (detectedEOL != NULL)
{
if (currentChar == detectedEOL) { lineCount++; }
currentChar = (char)byteBuffer[i + 1];
if (currentChar == detectedEOL) { lineCount++; }
currentChar = (char)byteBuffer[i + 2];
if (currentChar == detectedEOL) { lineCount++; }
currentChar = (char)byteBuffer[i + 3];
if (currentChar == detectedEOL) { lineCount++; }
}
else
{
if (currentChar == LF || currentChar == CR)
{
detectedEOL = currentChar;
lineCount++;
}
i -= BytesAtTheTime - 1;
}
}
for (; i < bytesRead; i++)
{
currentChar = (char)byteBuffer[i];
if (detectedEOL != NULL)
{
if (currentChar == detectedEOL) { lineCount++; }
}
else
{
if (currentChar == LF || currentChar == CR)
{
detectedEOL = currentChar;
lineCount++;
}
}
}
}
if (currentChar != LF && currentChar != CR && currentChar != NULL)
{
lineCount++;
}
return lineCount;
}
This abomination would certainly result in a better performance if we were not I/O bound but in our case any performance gained by unrolling the loop is dwarfed by the time taken to read the bytes from the disk. Therefore, we are going to stick to the non-unrolled version.
What we have come up with so far is by no means anywhere close to the most optimal solution specially if you are prepared to use unsafe combined with byte-masking but it is pretty much as far as I am prepared to go with optimising the algorithm for now as my main goal was to eliminate allocation.
Moment of Truth
Now that we have our candidate algorithm let’s run the benchmarks:
CountLinesSmart
1.txt | 00:00:00.5498381 | Gen0 - 0 | Gen1 - 0 | Gen2 - 0
2.txt | 00:00:00.5834317 | Gen0 - 0 | Gen1 - 0 | Gen2 - 0
3.txt | 00:00:03.0332798 | Gen0 - 0 | Gen1 - 0 | Gen2 - 0
4.txt | 00:00:25.3517502 | Gen0 - 0 | Gen1 - 0 | Gen2 - 0
5.txt | 00:04:13.1127603 | Gen0 - 0 | Gen1 - 0 | Gen2 - 0
Voila! Not only we improved the overall execution time but also we managed to be nice to the GC by not causing any collections.

How does it compare to wc -l?
In case you are wondering how fast you can count these lines in Linux (using time wc -l <file-name>), here are some numbers:
time wc -l <file-name>
1.txt | real 0m00.680s | user 0m0.000s | sys 0m0.031s
2.txt | real 0m00.719s | user 0m0.015s | sys 0m0.061s
3.txt | real 0m03.218s | user 0m0.015s | sys 0m0.046s
4.txt | real 0m25.966s | user 0m0.015s | sys 0m0.046s
5.txt | real 4m13.669s | user 0m0.015s | sys 0m0.000s
And finally, I have added this implementation to Easy.Common. You can use it by calling the CountLines extension method on any Stream. The source is HERE and unit tests are HERE.